ConcaveLabel Studio · Live Demo
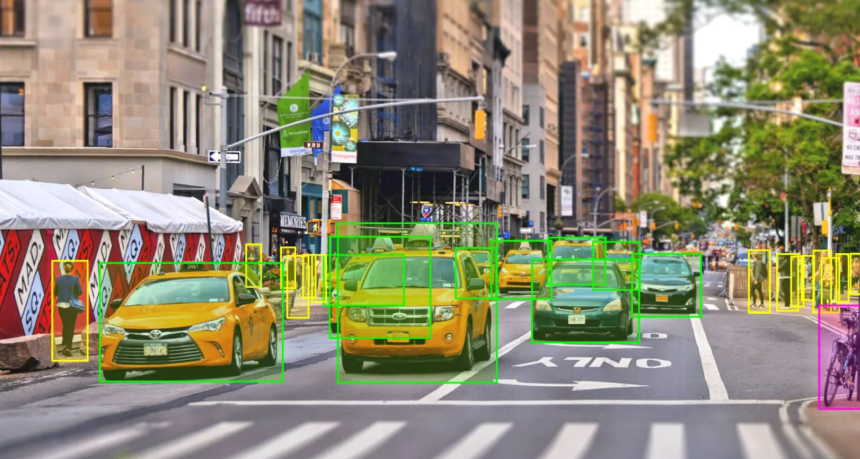
See the annotation pipeline in action.
Object detection, NER, and RLHF preference pairs, three task types, one QA-backed pipeline.

ConcaveLabel Studio · Active Session
● Tasks Completed: 1,247
● Annotators Online: 8
● Avg κ This Session: 0.86
✓ QA Passing